1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| package test;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import javax.imageio.ImageIO;
public class downImage {
public static void main(String[] args) throws IOException {
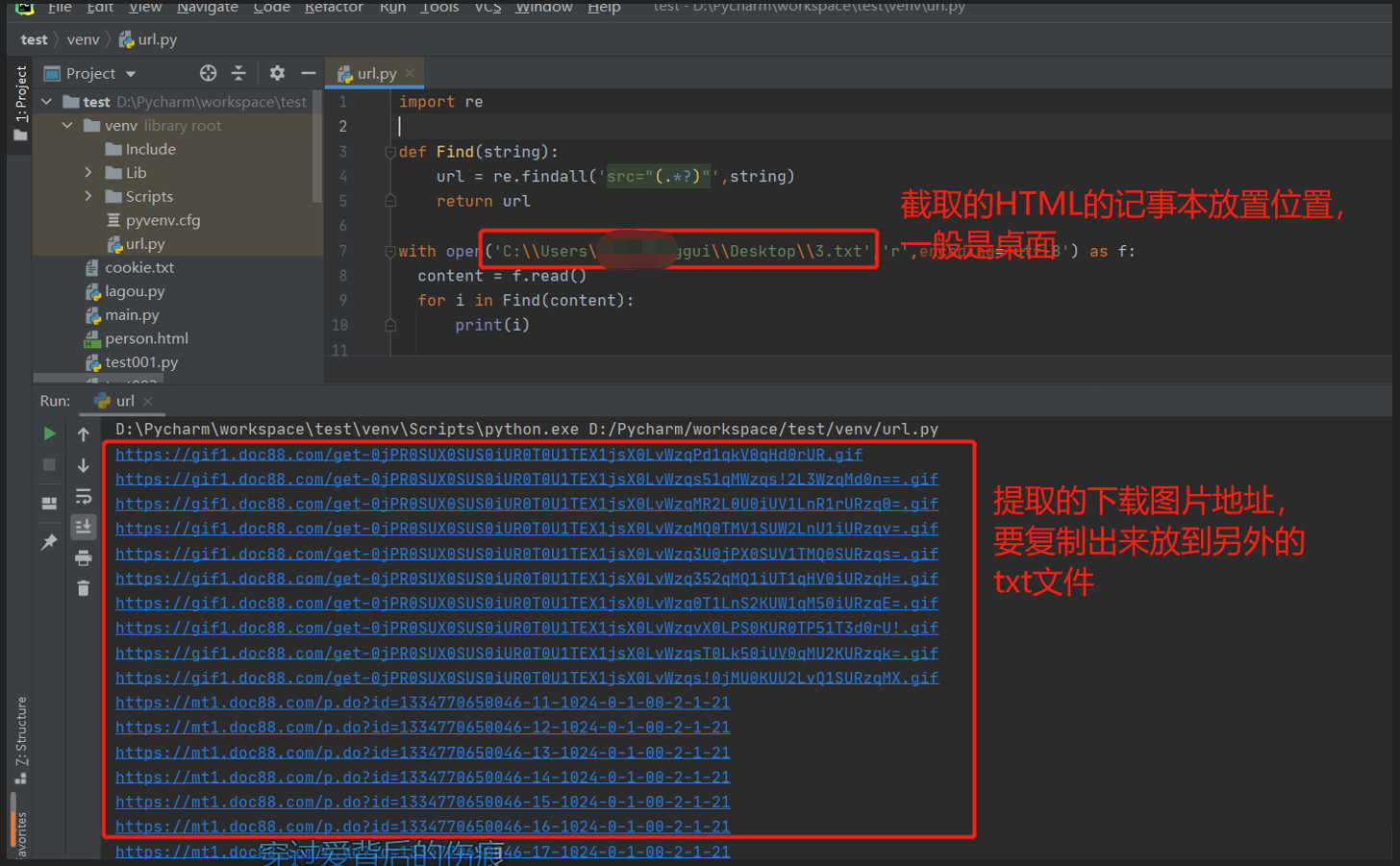
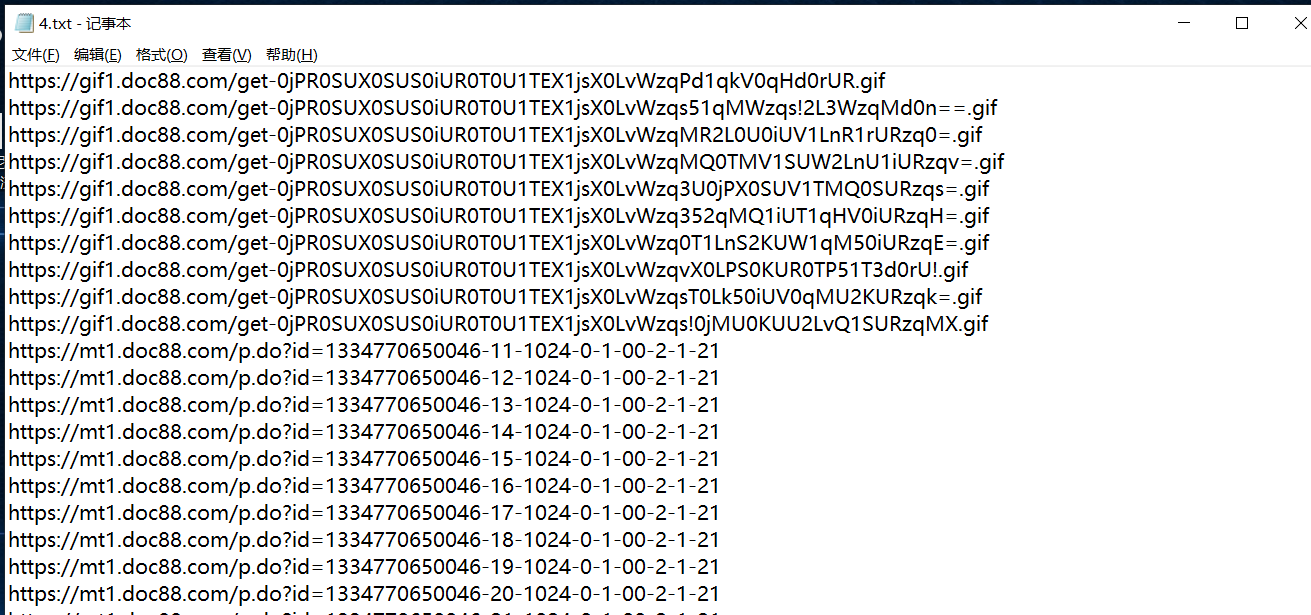
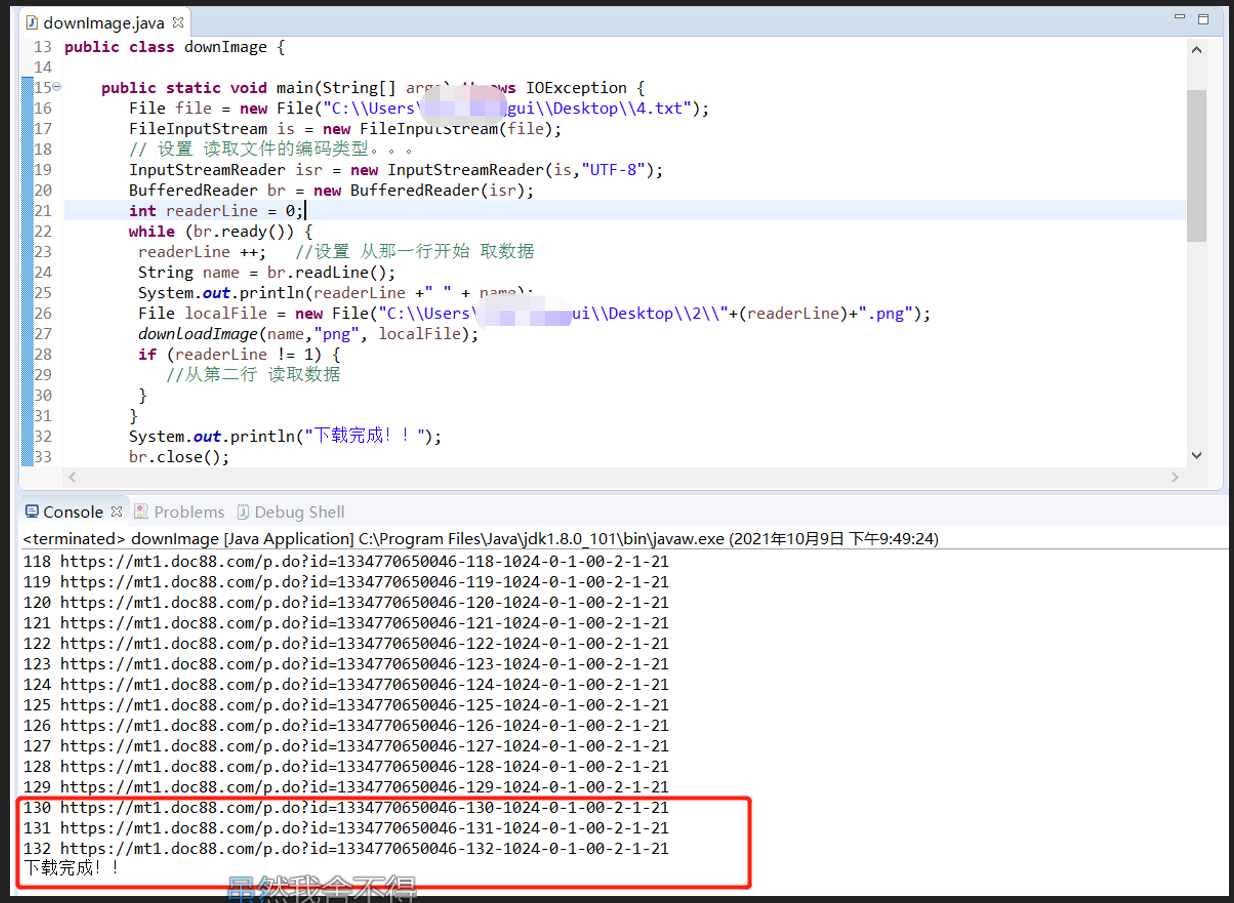
File file = new File("C:\\Users\\Lings\\Desktop\\4.txt");
FileInputStream is = new FileInputStream(file);
InputStreamReader isr = new InputStreamReader(is,"UTF-8");
BufferedReader br = new BufferedReader(isr);
int readerLine = 0;
while (br.ready()) {
readerLine ++;
String name = br.readLine();
System.out.println(readerLine +" " + name);
File localFile = new File("C:\\Users\\Lings\\Desktop\\2\\"+(readerLine)+".png");
downloadImage(name,"png", localFile);
if (readerLine != 1) {
}
}
System.out.println("下载完成!!");
br.close();
isr.close();
}
public static boolean downloadImage(String imageUrl, String formatName, File localFile) {
boolean isSuccess = false;
URL url = null;
try {
url = new URL(imageUrl);
isSuccess = ImageIO.write(ImageIO.read(url), formatName, localFile);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return isSuccess;
}
}
|